Blog
May 22, 2023
Google Cloud Platform's Dataplex: A potential middle ground solution




Dataplex is a new tool from Google Cloud Platform to govern data mesh. This article’s goal is to give an objective overview of Google Cloud Platform's (GCP) Dataplex solution, equipping readers with the knowledge needed to make an informed decision when choosing Dataplex as a tool to govern their data mesh. Before introducing Dataplex, we'll provide some context around the problem it solves.
Dataplex as a middle ground between data democratization and siloed ownership
In an ideal world, every user in the company has timely access to valuable insights derived from high-quality data. The data comes in the format they need, delivered via the tool they are familiar with. The security and access to data are tightly controlled to prevent unauthorized data access or leakage and to reduce risks associated with regulations such as Europe’s General Data Protection Regulation (GDPR). The data engineering teams don’t spend many hours building data pipelines and managing data silos. Instead, they spend it on delivering insights that impact decisions and move the business forward.
However, the reality is not so ideal. Many enterprises are struggling to maximize the value of their data. Two-thirds of data produced is never analyzed, because data is not easily accessible across multiple silos and the growing number of people and tools across the organization.
Companies often face the need to move and duplicate data from the silos. This enables analytics, reporting, and machine learning (ML) use cases, but also leads to data duplication, movement, and the possible degradation of data quality as a result. On the other hand, some companies leave the data distributed, limiting the agility of decision-making.
This is when the concept of data mesh and Dataplex comes in. Data mesh is a form of data architecture that acts as a middle ground between complete data democratization and siloed ownership. Zhamak Dehghani first proposed the concept in her 2019 paper, defining it as technology agnostic and scalable across the organization. It assumes the democratization (or decentralization) of data and ownership by domain. Examples of such domains could be orders, shipments, transactions, inventory, customers, etc. The data is owned by specific teams and treated as a product. Each domain contains data sources relevant to a particular business area, as illustrated below:
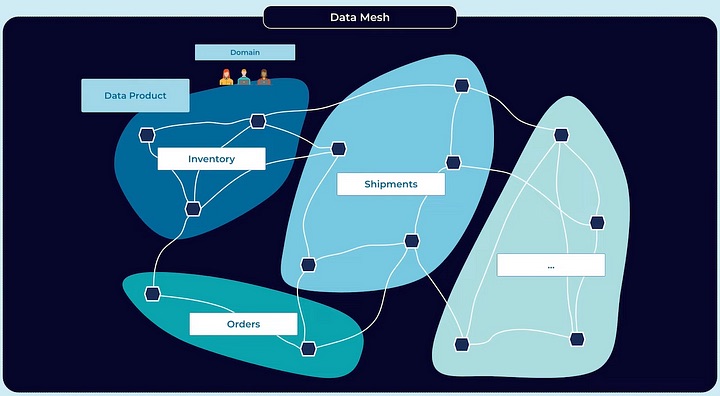
Hypothetical visualization for the data mesh.

What is Dataplex?
How do organizations allow the use of siloed data without the need for movement or duplication while maintaining the ownership and correct permissions across datasets and domains? Google’s answer to this is Dataplex. Defined as “intelligent data fabric” by GCP, it allows leaders to organize data lakes, marts, and warehouses by domains, enabling the data mesh architecture. In addition, it allows monitoring, governance, and data management. In terms of governance features, Dataplex has some similarities to AWS’s Lake Formation.
Dataplex provides a useful layer of abstraction of the data storage sources by using the following constructs:
Lake: A logical construct representing a data domain or business unit. For example, to organize data based on group usage, you can set up a lake per department (such as retail, sales, or finance).
A new lake can easily be created via the Dataplex console:
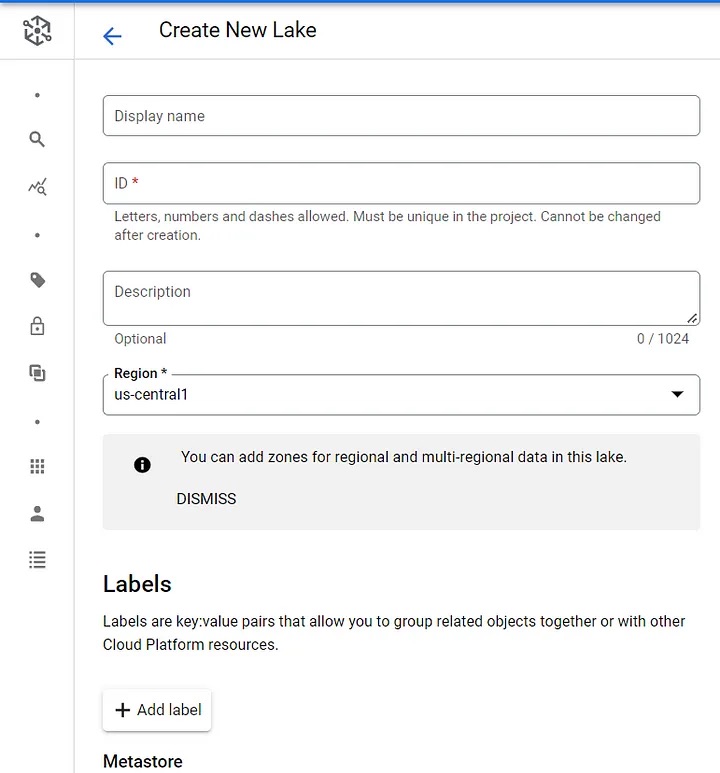
Dataplex lake creation.
Zone: A sub-domain within a lake, useful for categorizing data by stage (e.g., landing, raw, curated_data_analytics, curated_data_science), usage (e.g., data contract), or restrictions (e.g., security controls, user access levels). Zones are of two types: raw and curated.
We can create multiple zones within each lake either based on domain or data-readiness. The example below shows the zones by domain—e.g., fooddata.
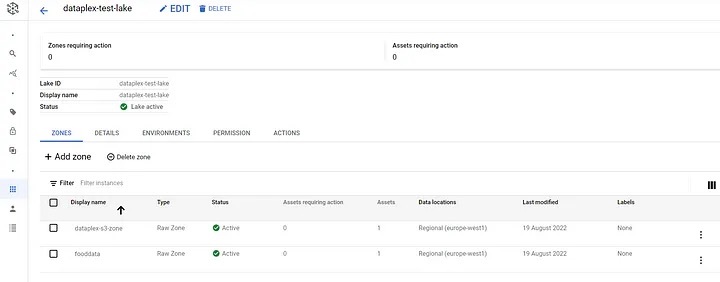
Example Dataplex zones by domain.
Raw zone: Data that is in its raw format and not subject to strict type-checking.
Curated zone: Data that is cleaned, formatted, and ready for analytics. The data is columnar, Hive-partitioned, in Parquet, Avro, Orc files, or BigQuery tables. It undergoes type-checking to prohibit the use of CSV files, for example, because they do not perform as well for SQL access.
The below example illustrates zones by different stages of data readiness:

Example Dataplex zones by stage.
Asset: An asset maps to data stored in either cloud storage or BigQuery. You can map data stored in separate Google Cloud projects as assets into a single zone.
Within each zone, we can add multiple assets that link to specific data sources. In the example below, we have added a BigQuery data set as an asset:
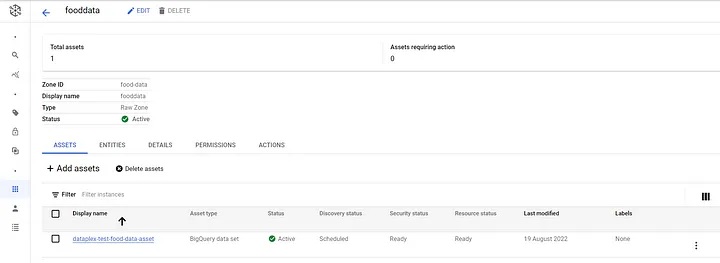
Example of a Dataplex asset.
Entity: An entity represents metadata for structured and semi-structured data (table) and unstructured data (fileset).
The visualization below shows an example of a Dataplex setup consisting of a single lake within the sales domain. It consists of three zones for raw, offline sales, and online sales data. Each of the zones contains data assets linked to specific data sources (e.g., Cloud Storage, BigQuery, or other GCP databases). Even though those sources are scattered in different storage systems or even GCP projects, the team members can easily access them via SQL Scripts, Jupyter Notebooks, or Spark jobs. In addition, automated data quality checks, data pipelines, and tasks are included within this data domain.
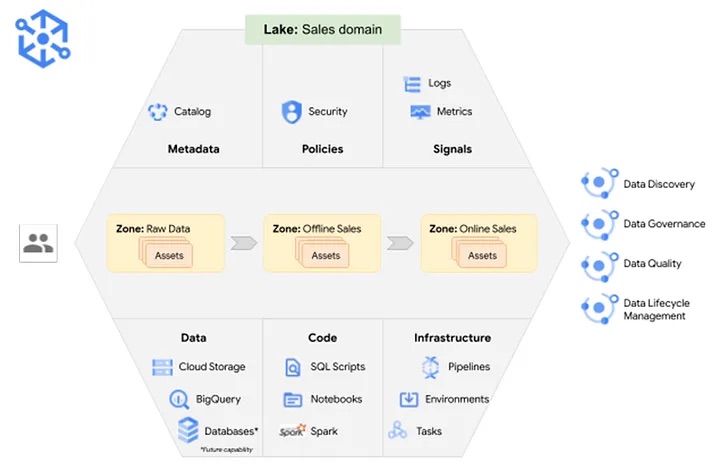
Example Dataplex set-up.
The advantages of Dataplex
Dataplex provides a single pane for data management across data silos and allows teams to map data to different business domains without any data movement. Here are some additional advantages of the tool:
Cost-efficient storage: Because the data doesn’t need to be moved and duplicated, you can store it in different data sources within GCP in a cost-efficient manner. This includes data being stored within different GCP projects. The data can be logically organized into business-specific domains.
Enforce data and access controls: The tool allows you to enforce centralized and consistent data controls across the data sources within a Dataplex lake at scale. It also provides the ability to manage reader/writer permissions on the domains and the underlying physical storage resources. At the same time, it enables standardization and unification of metadata, security policies, governance, and data classification. Organizations can apply security and governance policies for the entire lake, a specific zone, or an asset.
Easy integration: Dataplex integrates with Stackdriver to provide observability, including audit logs, data metrics, and logs.
AI/ML capabilities: Teams can use GCP’s built-in artificial intelligence (AI)/ML capabilities to automate data management, quality checks, data discovery, metadata harvesting, data lifecycle management, and lineage.
Metadata management and cataloging: Metadata management and cataloging allow the members of a domain to browse, search, and discover relevant data sources. The metadata is made available via integration with GCP’s Data Catalog. The illustration below shows the search tab within Dataplex.
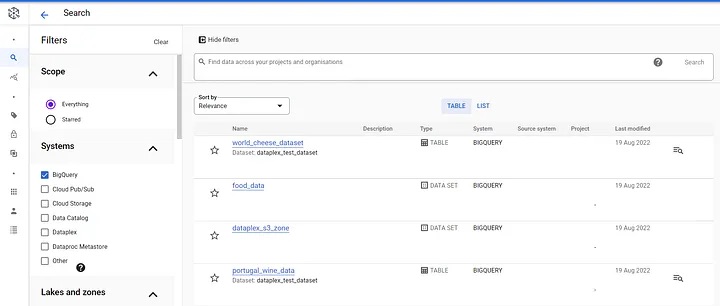
Searching for data within Dataplex.
Open-source integration: Integration with open-source tools such as Apache Spark, HiveQL or Presto.
GCP integration: Integration with GCP tools such as Cloud Storage, BigQuery, Dataproc, Dataflow, Data Fusion, Data Catalog, or GCP’s Notebooks. The example below shows how we can query the data within a Dataplex lake using BigQuery and load it in Notebooks.
Using BigQuery and Notebooks within Dataplex.
The disadvantages of Dataplex
While there are many advantages associated with Dataplex, it also carries some disadvantages:
GCP-only solution: Dataplex does not integrate with other large cloud vendors like AWS or Azure in the current release. This means that users cannot include data sources outside of GCP in the data mesh. This is an inconvenience for some large organizations that are using a multi-cloud approach.
Lack of maturity: Dataplex currently supports Google Cloud Storage and BigQuery. However, it is expected this list would grow as the tool is still relatively new. Furthermore, adding assets from all GCP regions is not available yet.
No on-premises integration: Many large organizations are pursuing a hybrid cloud model, meaning that some of their data are stored on-premises. Dataplex currently doesn’t allow integration with those data sources into the data mesh and is only limited to the ones stored in GCP.
Helpful resources
You can learn more about Dataplex via the following links:
Dataplex summed up
Even though Dataplex doesn’t support non-GCP cloud providers, on-premises data sources, or all GCP data sources, it is still very valuable for organizations using the GCP tech stack. The main benefits of centralized governance, integration with GCP tools, and AI/ML capabilities render it a great tool for enabling the data mesh architecture.
Interested in learning more? Reach out to us at marketing@credera.com.


Blog
May 23, 2023
Predicting house prices using Google's Vertex AI platform
Vertex AI combines data engineering, data science, and ML engineering workflows, enabling your teams to collaborate using a...

Blog
May 5, 2023
Unleash the power of AI-driven document intelligence
We’re explaining the challenges of traditional document processing and how AI-driven document intelligence transforms...


Podcast
Mar 15, 2023
Technology Tangents | Google trustbusters & ChatGPT cont.
With the recent lawsuit against Google, how should organizations react? Jason Goth and Vincent Yates discuss the...
Contact Us
Let's talk!
We're ready to help turn your biggest challenges into your biggest advantages.
Searching for a new career?
View job openings