



Microservices can be a great asset. They enforce high cohesion and loose coupling by design, can allow multiple teams to work in parallel, and allow individual components of a system to be scaled independently. Companies such as Netflix and Amazon have used them to great effect, and they’re an increasingly growing industry trend.
Yet for one client, we actually recommended re-architecting away from a microservice-based architecture into a monolith. “But wait,” you might say, “isn’t this the opposite of what everyone wants to do now?”
Microservices are not a silver bullet. They require careful design to ensure that each maintains its own domain or “bounded context” to avoid heavy coupling with another. If you encounter any of the following scenarios, you may not actually have “microservices”—you may just have a monolith split across multiple servers:
Deployments to one microservice always requiring another to deploy simultaneously.
Calls to one microservice always requiring calls to another.
Coupled schema changes due to sharing database tables.
The first two cases applied to this particular client. These services were so tightly coupled that they could not exist without each other. Their bounded contexts were not distinct, and they did not have a reason to scale independently. Data was duplicated across multiple databases with frequent synchronization issues where “eventual consistency” tactics failed. Most of this application’s corrupted customer profiles, performance issues, and complexity were actually a direct result of trying to adhere to a pattern it didn’t benefit from.
By re-architecting their platform, we were able to:
Simplify deployments.
Reduce cloud hosting fees.
Cut average response times in half.
Technical Details
The original configuration used nine AWS EC2 servers to host three instances of three microservices behind a separate load balancer per service type. The CPU and memory utilization of each microservice server barely went above 25% during peak load. Most calls required six network hops—one through each load balancer and microservice. Each microservice even had its own PHP framework startup penalty.


Hosting multiple services on the same server with localhost loopbacks for communication was our initial solution. We dropped the number of application servers down to three and hosted one instance of each service on each of them to utilize around 75% of their capacity during peak load. Now calls required at most two network hops—one for the load balancer and another for its destination server.
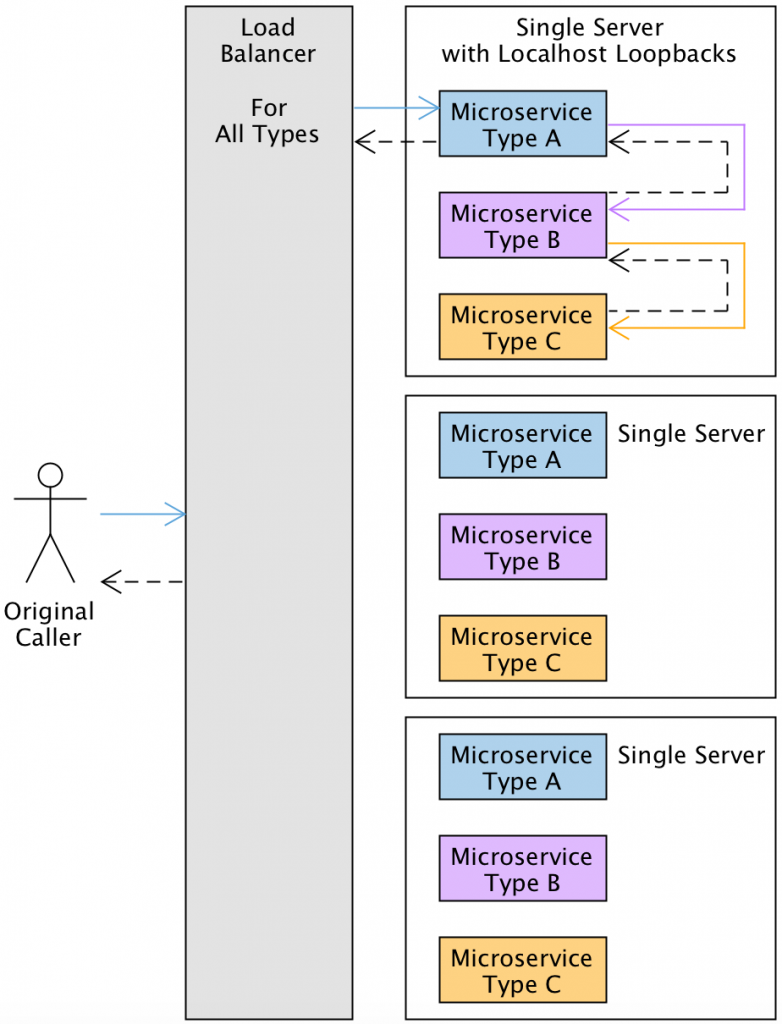
This resulted in immediate cloud hosting savings and halved our HTTP response times. We added CPU-based auto-scaling to spawn additional servers as contingency measures and used historical data to schedule additional server availability during known peak hours.
This is a picture of our New Relic performance before and after this change was implemented on November 14. The green section refers to time one service spent waiting on others. We continued to see lower transaction times for the same throughput levels going forward.

Note that if you host multiple web applications on a single server yourself, be sure to either increase the limit on your Linux file descriptors from the default Amazon Linux value of 1024, or remove the limit entirely. Otherwise, this approach could make you run out of socket connections before you hit CPU thresholds required to trigger cloud server auto-scaling.
Combining the codebases was the second step, so we wouldn’t have to perform workarounds to deal with the fact that each of the services actually shared the same bounded context. We wanted to be able to perform queries without using multiple schemas in the same SQL statements (which did not play nice with the application’s ORM framework), retrieve data without having to make additional “internal-use only” HTTP APIs when a service injection would have sufficed, and wanted to begin normalizing schemas by removing redundant components. Combining the services into a single application drastically simplified it, reducing technical debt and dead code.
Impact and Outcome
These cloud and application architecture optimizations resulted in immediate cost benefits by reducing yearly AWS costs and halving average response times. Long-term benefits were realized by allowing new features to be implemented with fewer redundant components and data synchronization complications.
Around half the development time and budget for each of these re-architecting efforts came from quality assurance (QA) testing. Despite being in production for several years, formal QA regression tests had not been developed for the platform prior to these changes. Developers had to create extensive documentation for the pre-existing APIs and third-party integrations, and spent significant time assisting QA in test generation and validation. However, the tests proved valuable for future development, amortizing their cost across subsequent QA cycles.
Takeaways
If you have multiple microservices you think may need to be combined, keep these items in mind:
Look for inefficiencies in inter-component and inter-service communication.
Find data bottlenecks that prevent or slow down new feature development.
Account for extensive QA regression testing for any large-scale change.
The up-front price of re-architecting may be high, but it can be recouped by reducing development time for future features or mitigating hosting fees. Business users might not see an immediate need for re-architecting since most changes may be internal; developers familiar with the application need to be consulted to see if they believe significant savings could be accrued through such an effort. Sometimes the real reasons new features are slow to market and perform poorly are simply due to architectural decisions that inhibit change and need to be revisited before driving forward.
For more information on application modernization, please contact us at marketing@credera.com or post in the comment section below.
Contact Us
Ready to achieve your vision? We're here to help.
We'd love to start a conversation. Fill out the form and we'll connect you with the right person.
Searching for a new career?
View job openings