





If your organization has ever considered using a data lake, you have probably come across articles like “Why Data Lakes Are Evil” and “Draining the Data Lake.” The authors of these articles, along with many other technologists, argue that data lakes are overly difficult to manage, expensive, and unnecessary. Data overindulgence naturally follows from this big data “store now, find value later” mentality.
Data lakes have their drawbacks, as do all data storage solutions. The rise of the data lake was at least in part due to struggles with the data warehouses most enterprises adopted first. High cost and rigidity forced many organizations into a slow crawl toward being truly data-driven. Boasting the perhaps double-edged appeal of cheap and flexible storage, data lakes took the world by storm. Unfortunately, with the loss of the structure of traditional data warehouses, many data lakes became unmanageable data swamps, overflowing with data type mismatches, unrealized changes to raw data schemas, and too much data to process. But what if we want to have our cake and eat it too with cheap and flexible storage that’s still structured and usable?
We wouldn’t be human if we didn’t try; enter, the data lakehouse. The data lakehouse promises both the structure of a traditional data warehouse and the flexibility of a modern data lake. When properly designed and implemented, the data lakehouse can be the best of both worlds when it comes to balancing cheap, effective data storage with the structure of traditional data architecture.
The explosion of the data tooling landscape and advancements of the cloud platform providers unlocks near-endless possibilities for data architecture implementation. The data lakehouse is no exception to this. With a wide array of tooling options to buy and new accelerators to build your own, it can be difficult to decide what approach to take for your organizational needs.
In this article, we will briefly explore three of the most-common approaches for data lakehouse implementation.To keep things more comparable, we will choose AWS as the common cloud platform in each of the three approaches.
Approach #1 – The Lake-Centric Lakehouse
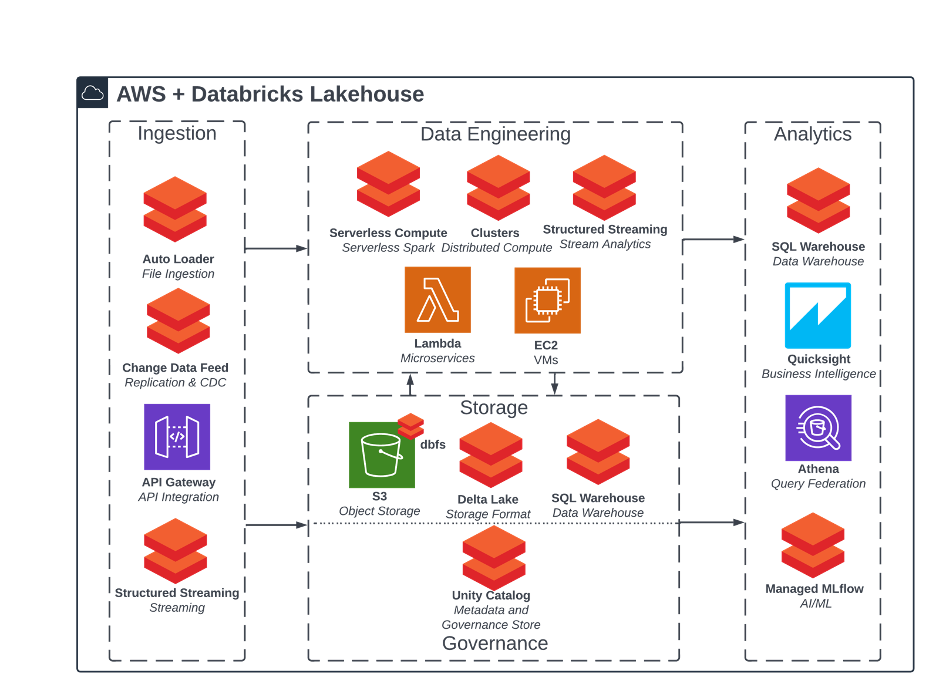
Figure 1: Reference architecture for Databricks lakehouse on AWS

The Databricks platform offers a lake-centric approach to the data lakehouse. Most of your transformations and other heavy lifting is happening within the data lake itself. Databricks is the original creator of the Spark platform, one common and widely used technology stack for the processing of big data in the realm of data lakes.
This Databricks, lake-centric approach typically won’t include a persistent, physical data warehouse. Instead, Databricks platform components (Delta Lake 2.0, Unity Catalog, Databricks SQL, and more) meet the core data capabilities required to lend structure and reliability to the lake. The Databricks platform enables ACID and transactional support, metadata store and history, auto-scaling compute engine, governance and security model, and many more necessary features to impose order on unruly data lakes.
Databricks values providing an open platform that builds heavily around the open-source community. With a broad partner network and easy ability to bring custom packages, Databricks provides a widely extensible platform capable of handling all analytics use cases. This flexibility can come with its natural price—sophisticated and complex implementations tend to be “code-heavy” in nature and generally have a higher custom engineering burden than the other approaches.
Best Feature
The lake-centric Databricks approach is known for enabling advanced analytics as it provides seamless integrations within its persona-based Machine Learning (ML) workspace, supporting the full lifecycle of machine learning operations (MLOps) via Managed MLflow. This approach is optimal for organizations with high volumes of large, streaming data or event sources, which can be ingested directly into the data lake while simultaneously being processed with Delta Live Tables or fed into downstream ML models. The open-source platform provides significant flexibility, as it allows for use of the latest public libraries, packages, languages, and visualizations supporting custom advanced analytics solutions.
Biggest Challenge
The lake-centric approach may not be ideal for businesses that historically rely heavily on a traditional data warehouse. If your organization primarily just needs standard, descriptive analytics in the form of regular SQL-based reporting and business intelligence tooling, the Databricks approach may not be a good fit. If you are migrating any existing and mature data warehouse models, the Databricks platform can introduce more complexity (e.g., around infrastructure management in leveraging the clustered compute model) than migrating to a more similar platform.
Approach #2 – The Warehouse-Centric Lakehouse
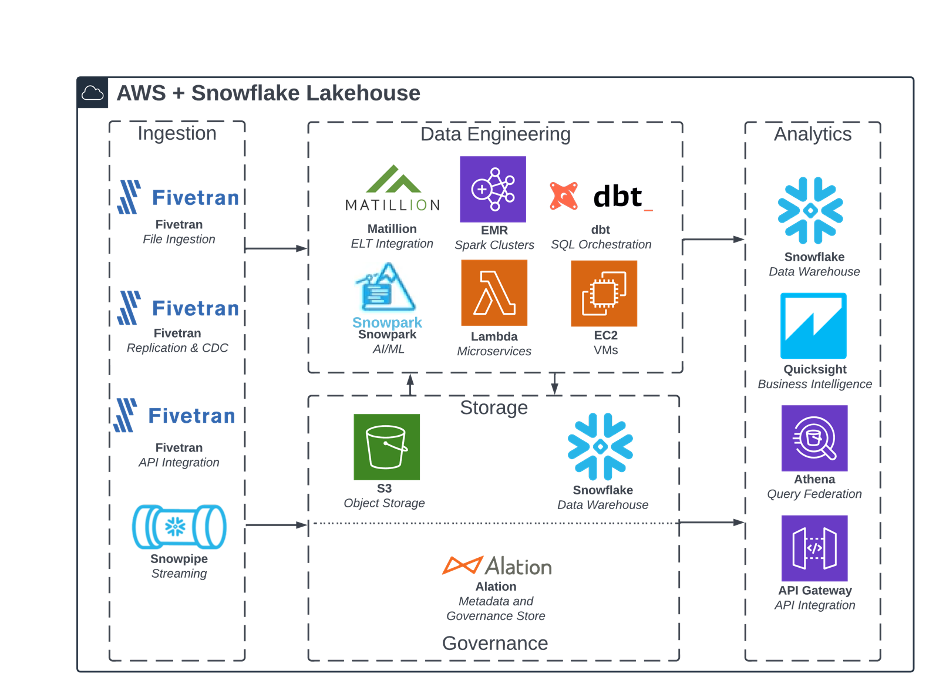
Figure 2: Reference architecture for Snowflake lakehouse on AWS
Snowflake is almost universally lauded as the best-in-class data warehouse solution. The modern data warehouse platform has streamlined traditional data modeling and descriptive analytics, removing much of the standard maintenance, performance, and cost-optimization pain points that plague other data warehouse solutions. This is achieved through features like usage-based billing with automatic “pause-when-unused” support, automatic query optimization, micro-partitioning, continuous data protection, and many more.
The Snowflake warehouse-centric lakehouse builds upon Snowflake’s best-in-class management features of data structures, combining them with cost-effective data lake storage. While shown here on top of an AWS cloud environment, Snowflake easily integrates with all the major cloud providers. Regardless of underlying storage details, Snowflake delivers an immersive and intuitive user experience on top of their slick technology stack. The platform uses SQL as its universal language, which makes platform management and usage accessible for most end users.
Though Snowflake is still playing catch-up on more of the Lake-centric advanced analytics, recent platform enhancements (i.e., Snowpipe, Snowpark) are helping close that gap. True real-time applications and artificial intelligence/machine learning innovation may be better served with a lake-centric or hybrid approach, but for all other use cases, a Snowflake warehouse-centric solution remains a compelling lakehouse approach.
Best Feature
Snowflake includes a truly best-in-class feature for data product management: zero-copy clones. This feature allows an object (i.e., database, schema, or table) to be “cloned” and modified independently of the source object, tracking only the changes to that object in a separate database. No other lakehouse platform can quite match this Git-like versioning layer, which empowers the seamless and cost-efficient development, testing, troubleshooting, and sharing of data products.
Biggest Challenge
Since SQL is the natural dialect for the warehouse-centric approach, it is more difficult to perform certain advanced analytics. While Snowflake certainly supports a variety of tooling and interfaces in addition to standard SQL, it can be a challenge to develop and maintain true real-time streaming data applications in Snowflake, especially when compared to Databricks or a mature AWS-native platform. Similarly, Snowflake’s Snowpark is somewhat behind in its more advanced machine learning use cases than Databricks’s Machine Learning workspace with Managed MLflow and Amazon’s Sagemaker platform.
Approach #3 – The AWS Native Hybrid Lakehouse
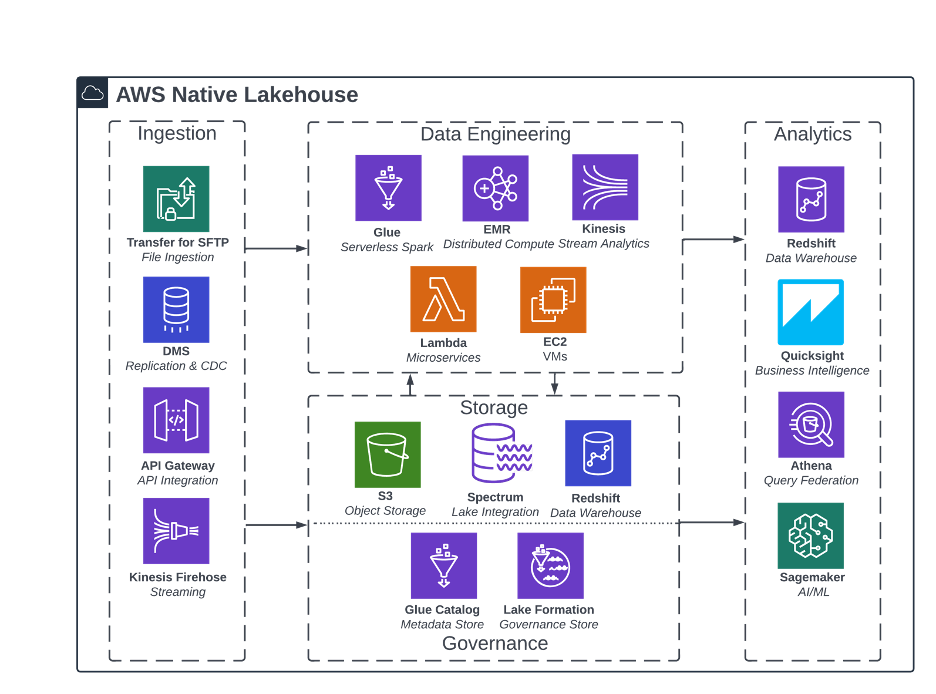
Figure 3: Reference architecture for AWS-native lakehouse
Finally, the AWS-native lakehouse presents a modular approach, where the data lakehouse is pieced together with a variety of its services. Within AWS, there is a clear distinction between the data lake components (S3 for storage, Glue for metadata, Lake Formation for security) and the data warehouse components (Redshift with Spectrum for lake integration).
While these components are markedly discrete, AWS constantly strives to make the integration between these core analytics and storage services as seamless as possible. Redshift Spectrum is a key feature, allowing users to query and join structured data residing in both S3 lake and Redshift warehouse storage layers without needless copies or pre-processing.
Additionally, Lake Formation has rapidly expanded in recent years to provide a more robust security and governance layer around the metadata stored in the data catalog (Glue). And on the data engineering side, AWS has really leaned into the “serverless” architecture, releasing offerings within Spark (EMR) and warehouse (Redshift) compute technologies, to complement Lambda, Glue, and other existing AWS serverless infrastructure.
Best Feature
Being a hybrid of the previous two approaches, the AWS-native lakehouse has the key benefit of flexibility, in both architecture and delivery. An organization can mature either data lake or data warehouse, and later integrate the two when the need arises. This flexibility pairs nicely with an agile delivery model, enabling organizations to gradually mature their data platform in support of their use cases.
Biggest Challenge
While modularity supports flexibility, it also hinders cohesion. Various user personas will likely interact with very different interfaces within AWS, even if some key services will overlap. Significant custom build and maintenance is required to support the full breadth of analytics personas, and the user experience can leave something to be desired. Snowflake and Databricks as platforms provide a more streamlined experience out of the box.
Which Cloud Lakehouse Approach Is Best for You?
Each organization will have unique ingestion, storage and governance, data engineering, and analytics requirements. The following table highlights some of the most important considerations for these dimensions to your data lakehouse.
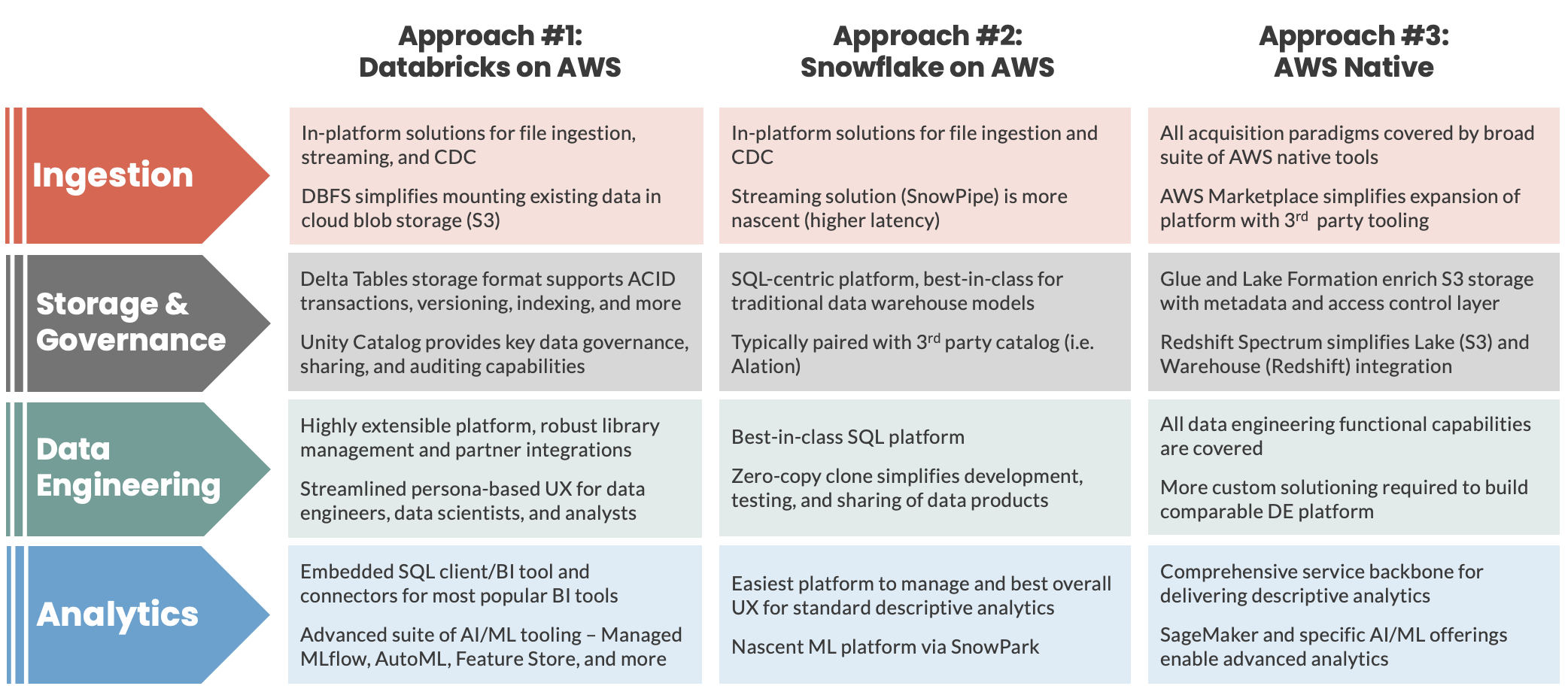
Figure 4: Recap of three lakehouse approaches and key considerations
Want to Learn More?
These are only three of the many approaches to the data lakehouse. There is no one-size-fits-all solution when it comes to an organization’s data architecture. Understanding what type of, if any, data lakehouse is the right fit for you should be done with proper due diligence. If you have any questions about the various approaches for data lakehouse implementation, feel free to contact Credera at marketing@credera.com. We would be happy to help you solve your current challenges.

Whitepaper
Jun 17, 2022
Credera's Cloud Transformation Framework
Not seeing the results expected from your cloud adoption journey? Credera has developed a Cloud Transformation Framework to enable companies to focus on the big picture of...
GET THE WhitepaperBlog
May 25, 2022
Behind Every Cloud Transformation, There’s Change Management
Credera has recently completed a large-scale migration of a core government analytics service from a legacy on-premises...

Podcast
Aug 31, 2022
Technically Minded | Maximizing Your Organization's Cloud Transformation Journey
With the increase of cloud investment, it’s no longer a question of if the cloud is a differentiating factor, but how...

Contact Us
Let's talk!
We're ready to help turn your biggest challenges into your biggest advantages.
Searching for a new career?
View job openings