




Microservices have definitely hit it big. The architectural approach has made it into the mainstream by proving itself as a legitimate way to build fault-tolerant, highly available, horizontally scalable systems. With big name adopters in the high-performance tech industry such as Netflix, Amazon, and eBay, it is wise for the software architect to understand the approach and ask the question: is a microservice approach the right choice for my application?
With major adoption comes the risk of over-adoption. Just because it is a legitimate approach does not mean that it is the right approach for all projects. However, even when a legitimate application for microservice adoption is identified, there is such a thing as “overdoing it.” There are pushes in some circles to create the smallest microservices possible, down to what people are calling “nanoservices” and even “picoservices.” Some camps advocate that blocks of code down to the 10-line range are legitimate candidates for becoming individual services.
Microservices are definitely not a silver bullet, and there are a number of costs associated with them. By having a solid understanding of the costs, you will have a better understanding of what you’re getting into and will be able to make better decisions when compartmentalizing your system. In this article, we will dive into just one commonly overlooked cost of implementing and deploying a microservice: the performance expense of the service tier itself.
Service Tiers Can Be Expensive
The performance and bandwidth overhead induced by wrapping a piece of functionality in a microservice can be expensive. When creating a microservice, the cost of the entire service tier—including serialization and data transmission—is often overlooked. If the functionality you choose to implement as a microservice is not carefully thought out, you may find that your microservice performance may not have the appreciable benefits you are shooting for. The service tier, I/O, and serialization combined can have a notable negative impact on system performance and inherently chip away at the benefits of a microservice-based architecture approach.
Let’s consider one of the most common approaches for building a microservice: a REST-based API, which will speak JSON over HTTP. For any given request, the following steps must be taken:
Serialize the data to JSON, create HTTP request.
Transmit request (over-the-wire if on a different machine).
Deserialize the request.
Perform the work.
Serialize the response, create HTTP response.
Transmit response (over-the-wire if on a different machine).
Deserialize the response.
There are a number of technologies and frameworks that can make the ancillary tasks (essentially everything but doing the actual work) extremely simple and fast to implement. However, that does not necessarily make it cheap from a CPU-cycle and bandwidth perspective. I’ve put together an extremely simple microservice to illustrate the point using Dropwizard, a lean and mean performant API for implementing java-based REST services. Under the hood, Dropwizard uses Jersey as the JAX-RS REST implementation, Jetty as the HTTP transport layer and Jackson for object serialization. This extremely simple microservice exposes two different math functions which perform work on a collection of numbers. It can add them all together and perform a 10th-order polynomial curve-fit utilizing the Apache Commons Math library. You can download and view the code for this microservice on GitHub.
Simple Microservice Test
Before we dive into the data, a few notes on the environment and collection strategy: I collected this data by running the microservice on a 2014 MacBook Pro. The data was extracted with the YourKit JVM profiler with full-tracing style profiling enabled. The numbers used to seed the requests were randomly generated doubles and the same values were used across each test method type. All of the requests were made over a hard-wired 1000BASE-T ethernet connection.
When doing JVM performance profiling, you’ll notice that the first run through of a call stack will generally be substantially slower than subsequent invocations because the later invocations don’t incur the initial overhead of classloading, initialization, etc. Because of this, I “primed the pump” by making the requests multiple times to allow the response times to settle before collecting the data you see below. This is a very important step to get legitimate performance data when profiling within a JVM-based language.
To obtain the performance data, I looked at the amount of time spent servicing an entire request, the time spent within calls related to I/O and serialization (focusing on Jackson packages), and the time spent in the respective math functions. Here is an example of how I sampled the data points: This particular call is a REST-based invocation where the microservice was running on a different machine than the one that generated the request.
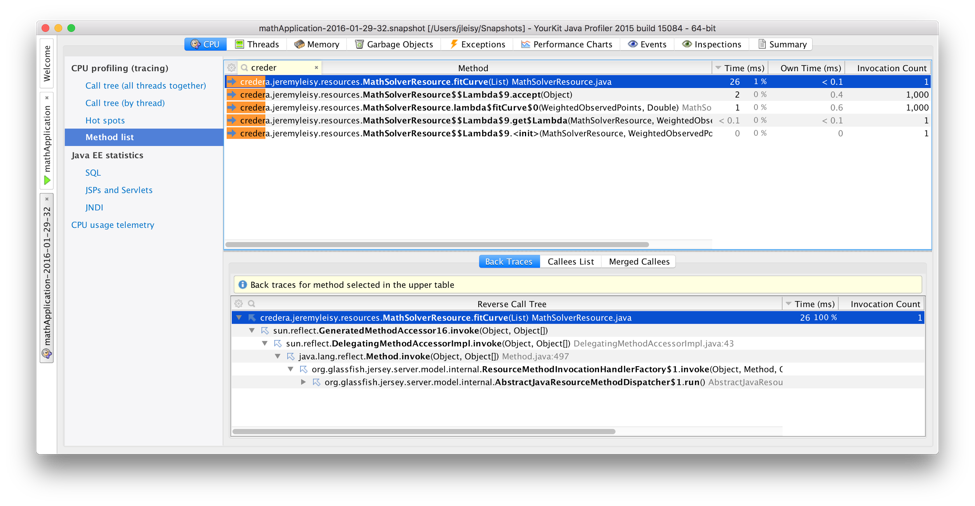

Here you can see that during this particular request (a remote REST invocation of a polynomial curve-fit against 1,000 doubles), 26ms of time was actually spent “doing the work” of adding the numbers together.
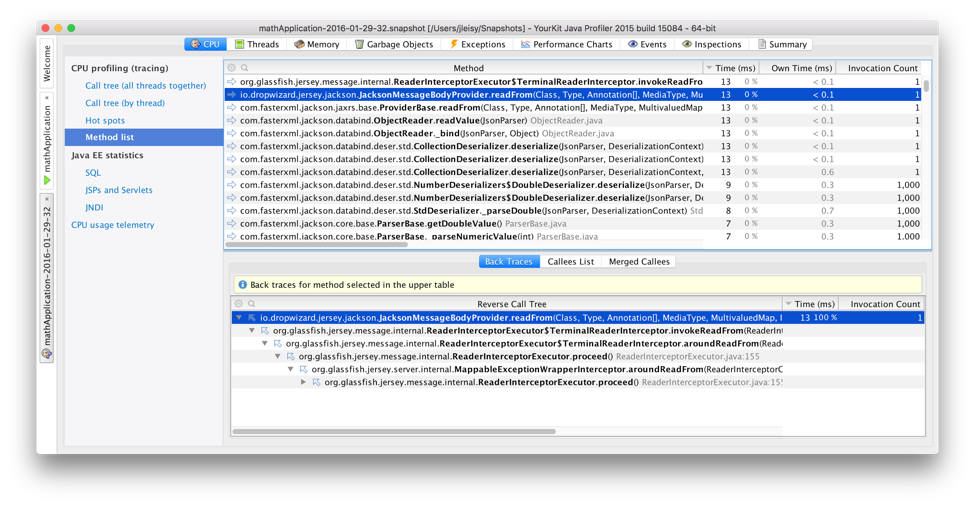
By disabling call filtering and focusing on the appropriate classes, we can see that 13ms of the total 50ms of this request was spent on serialization. The rest of the execution time was spent performing the Jetty/HTTP/DropWizard overhead required to service the request. This approach was used to collect the performance data for the complete data set.
Results
By putting functionality that is not appropriately complex or demanding into a microservice of its own, the performance cost of the service tier will induce a relative performance penalty, which can effectively negate many of the desired benefits. Let’s take a look at some data:
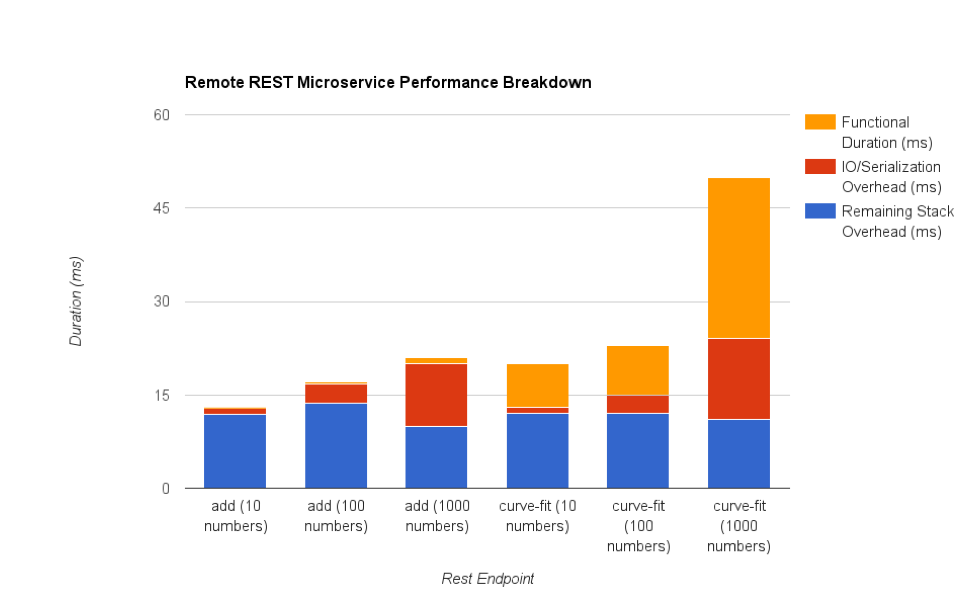
With the chart, there are a few trends that become obvious. As the amount of data transmitted increases, so does the time performing I/O and serialization. Although this may seem obvious, the magnitude of the time required is worth noting. The more data your application has to pack up and ship over the wire, the less relative time your application is spending doing actual work. Consider the double values we are sending over the wire in this example. A double in java is represented in memory with 8 bytes of data. When converted to JSON, these same doubles are taking up around 19 bytes including the decimal point, because each digit is being represented as a single character in a string. That means that to serialize a full precision double from memory to JSON, you’re well over doubling the amount of data required to represent it. In the case of the larger payload in this example, the size of the HTTP request body is 27kb. For adding numbers, 47% of the time servicing the request was spent dealing with I/O and serialization. Take heed: larger payloads will encounter larger serialization and transmission times, so if the data you need to transmit to your microservice is sizeable, consider if this is an overhead you’re willing to take on.
If you must serialize lots of data to your microservices, there are indeed other ways to package the data, as long as you’re willing to be flexible with your payload types. An example would be utilizing Google Protocol Buffers instead of JSON. This can be substantially more efficient for serialization and is still doable over HTTP/REST, if you are willing to make the tradeoff of communicating with such a protocol. You can also skip REST altogether and utilize other communication protocols and tools, such as Apache Thrift.
From the chart, you can also see that the time spent performing the rest of the miscellaneous functionality required to provide the RESTful API is generally consistent among the calls (this includes things like the full HTTP request parsing and response generation). This overhead will increase as the microservice has to handle other more complex things such as logging, explicit metrics recording, authentication/authorization, and anything else your organization needs. This sort of performance hit can be considered a “flat-tax” which must be incurred for the servicing of each request. In the case of the extremely simple function of adding numbers together, only 2-5% of the time servicing the request was actually performing the desired work, with up to 91% of the time being spent in the complete service tier overhead. If the functionality being encapsulated by your microservice is not complex or expensive enough, then this flat tax will substantially decrease overall performance. In the case of this simple microservice, we took a 1ms operation (adding 1,000 doubles together) and turned it into a 21ms operation—clearly a bad choice!
The more expensive operation of the 10th-order polynomial curve fit starts to reflect a lesser impact against the overall microservice implementation, due to the higher performance cost of the operation being executed. In the case of the most expensive request, 52% of the time was spent actually “doing work” as opposed to just dealing with the service tier overhead. Although an improvement, this example still has a substantial amount of time spent dealing with overhead not directly associated with the actual work.
For those interested in the complete data, here is a table depicting the final results of the various invocations of the two endpoints in this microservice:

Choose Your Microservice Functionality Wisely
This simple example was built to illustrate a point: there is a cost associated with encapsulating a piece of functionality within a microservice. If the specific functionality is not chosen properly, this cost may trump the benefit of creating a microservice in the first place. Obviously this is a very simple example: it would not be wise to implement a microservice that simply adds numbers together in your system. When you have microservices doing more complex and expensive things (say, image processing, accessing databases, and/or performing complex data analysis), the cost of the service tier becomes much less expensive in comparison. When chosen properly, the cost of the service overhead for whatever functionality you wish to expose as a microservice will begin to drop to the “noise” level. In addition to having the benefit of separation of concerns, you are also able to realize much better system performance benefits by having the ability to scale your system horizontally.
Selecting functionality which is appropriate for individual microservices is just one aspect to consider when building out a microservice architecture: things like service discovery, authentication/authorization, and logging approach all need to be considered. Understanding the costs and benefits of different options will absolutely save you and your team time and money in the long run.
What’s your approach to decomposing functionality into microservices? Please feel free to ask any questions in the comments section below, and connect with us on LinkedIn and Twitter @CrederaOpen.
Contact Us
Let's talk!
We're ready to help turn your biggest challenges into your biggest advantages.
Searching for a new career?
View job openings